







Zanim powstały pismo, klawiatury i wszechobecne ekrany dotykowe, ludzkość komunikowała się w najstarszy możliwy sposób: głosem. To była nasza pierwsza „interfejs użytkownika”. I choć technologia przez wieki zdążyła ubrać komunikację w tekst, dziś — trochę jak moda na winyle — głos wraca na salony. Tyle że w zupełnie nowej odsłonie.
Nowe modele Voxtral, stworzone z myślą o zrozumieniu mowy, mają pomóc przywrócić głosowi należne mu miejsce w cyfrowym świecie. I, trzeba przyznać, robią to z rozmachem.
Co to jest Voxtral?
To dwie wersje potężnego modelu rozpoznawania i rozumienia mowy:
- Voxtral Small (24B) — dla dużych, produkcyjnych wdrożeń,
- Voxtral Mini (3B) — do działania lokalnego lub na brzegu sieci (edge).
Obie wersje są open-source (licencja Apache 2.0), dostępne do pobrania, do testów, a także przez API. W skrócie: technologia mowy klasy premium, ale w modelu open i za ułamek ceny rynkowej. Trochę jakby ktoś dał Ci Ferrari do jazdy po ścieżce rowerowej – z pełnym baku i bez limitu kilometrów.
Gdzie konkurencja się potyka, Voxtral przebiega sprint
Dotychczas ci, którzy chcieli mieć dobry system rozpoznawania mowy, stawali przed wyborem: albo otwarte, ale niedokładne modele ASR (Automatic Speech Recognition), albo zamknięte, drogie i trudne do kontrolowania API od gigantów. Voxtral to trzecia droga: wysoka jakość, niska cena i pełna kontrola.
A co konkretnie potrafi?
- Transkrypcja długich form – do 30 minut mowy,
- Zrozumienie audio – do 40 minut z kontekstem,
- Wbudowane Q&A i podsumowania – bez potrzeby żonglowania modelami,
- Obsługa wielu języków – w tym angielski, hiszpański, francuski, niemiecki, portugalski, hindi i inne,
- Wykonywanie komend głosowych – można mówić, a system od razu „działa”, bez dodatkowego kodowania,
- Obsługa tekstu – bo pod maską siedzi Mistral Small 3.1.
Voxtral potrafi więc nie tylko słuchać, ale i zrozumieć. Jak twój ulubiony profesor z uniwersytetu — tylko że nie zasypia po 22:00.
Transkrypcja na medal
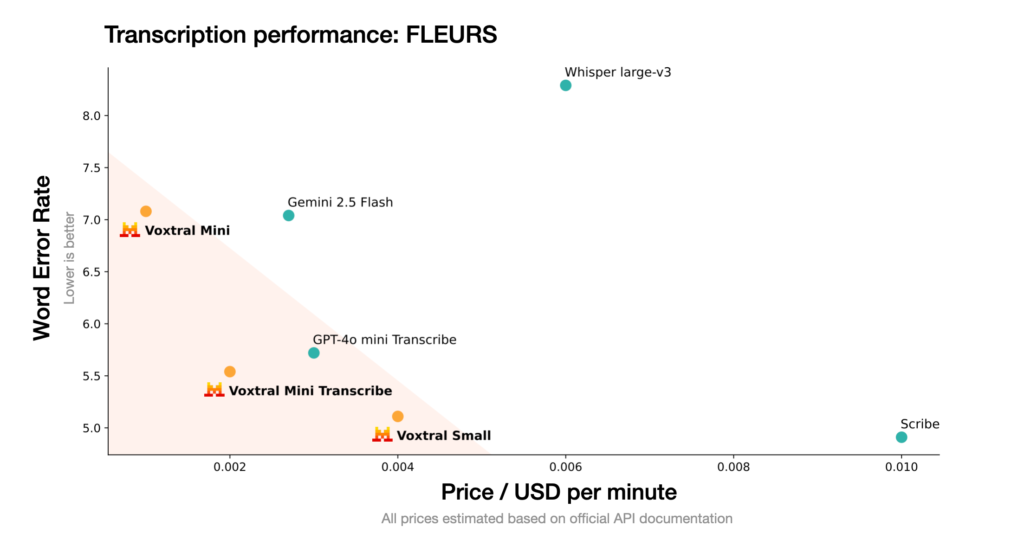
Na benchmarkach Voxtral zostawia konkurencję w tyle. W testach takich jak LibriSpeech, Mozilla Common Voice czy FLEURS, model bije Whisper large-v3 od OpenAI i inne rozwiązania – i to zarówno w języku angielskim, jak i w wielu europejskich językach. Co ciekawe, Mini Transcribe (czyli wersja tylko do transkrypcji) przewyższa Whispera i to przy ponad dwa razy niższej cenie.
Kto powiedział, że taniej znaczy gorzej?
A to dopiero początek
Voxtral nie zatrzymuje się na rozumieniu słów. Modele potrafią odpowiadać na pytania zadane wprost do dźwięku, tłumaczyć, a nawet analizować emocje i rozróżniać mówców (to już niebawem). I — co istotne — są gotowe na produkcję w firmach, które potrzebują prywatności, szybkości i kontroli.
Chcesz więcej? Proszę bardzo:
- Możesz je pobrać z Hugging Face.
- Możesz odpalić przez API (już od $0.001/min).
- Możesz przetestować w Le Chat – nowej funkcji czatu głosowego.
Voxtral dla firm i geeków
Dla tych, którzy chcą czegoś więcej: prywatne wdrożenie, dostosowanie pod branżę (np. prawo, medycyna, obsługa klienta), jeszcze dłuższe konteksty, rozpoznawanie emocji i inne cuda. A na dokładkę – specjalne wsparcie inżynierskie dla firm, które chcą wpleść Voxtrala w swoje produkty i procesy.
Voxtral to więcej niż kolejny model AI. To ukłon w stronę czegoś pierwotnego – mowy – ale ubrany w nowoczesną technologię i gotowy do działania tu i teraz. Ciche rewolucje czasem zaczynają się właśnie… od głosu.