






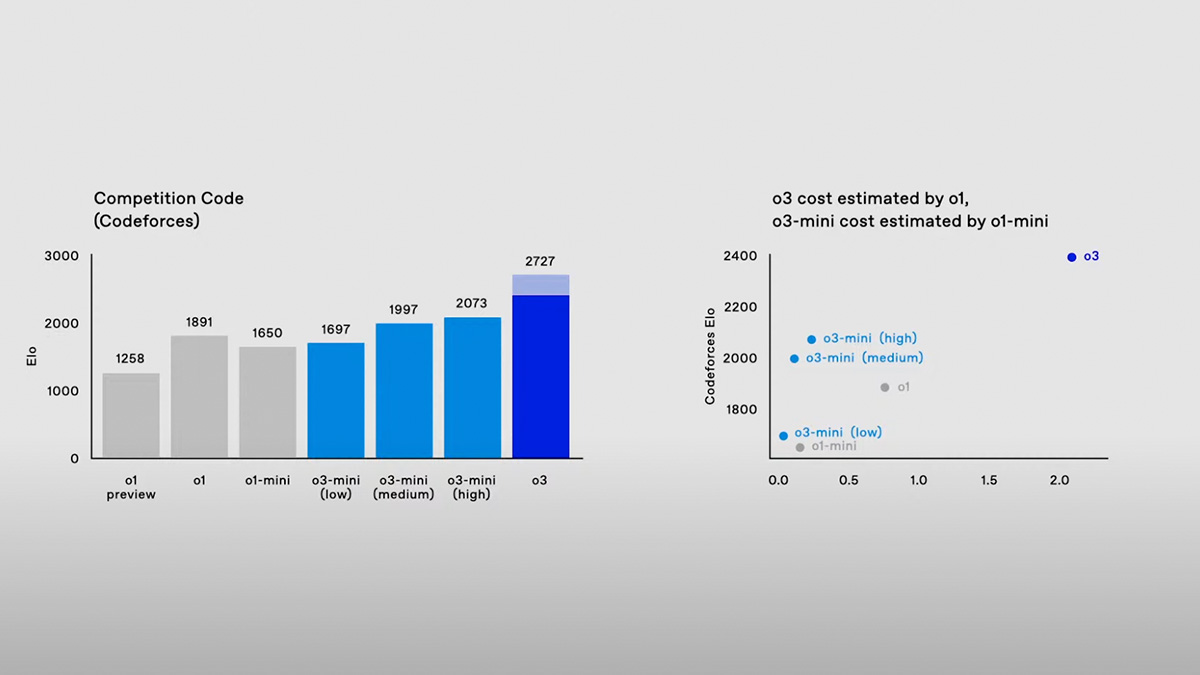
OpenAI zaprezentowało w piątek nową rodzinę modeli sztucznej inteligencji o nazwie o3, które według firmy są bardziej zaawansowane od swoich poprzedników, o1, a także od wszystkich innych dotychczasowych produktów startupu. Sekret tego postępu? Zwiększenie mocy obliczeniowej w czasie działania modelu, co OpenAI zapowiadało już wcześniej. Jednak równie istotnym elementem jest nowy paradygmat bezpieczeństwa, który firma wdrożyła podczas szkolenia modeli z serii „o”.
Wraz z premierą nowych modeli, OpenAI przedstawiło także badania nad koncepcją „deliberative alignment” (z ang. deliberacyjnego dopasowania). To najnowszy sposób firmy na utrzymanie zgodności modeli AI z wartościami ich twórców. Metoda ta pozwala modelom, takim jak o1 czy o3, „rozmyślać” nad polityką bezpieczeństwa OpenAI podczas działania – czyli w momencie, gdy użytkownik wpisuje swoją komendę i oczekuje na odpowiedź.
Nowe podejście do bezpieczeństwa AI
Badania dowodzą, że dzięki deliberacyjnemu dopasowaniu model o1 lepiej przestrzega zasad bezpieczeństwa firmy, jednocześnie zmniejszając liczbę odpowiedzi na „niebezpieczne” pytania, czyli takie, które OpenAI uznaje za niestosowne. Co więcej, poprawiono zdolność modelu do odpowiadania na nieszkodliwe zapytania.
Bezpieczeństwo w AI to obecnie gorący temat. Rosnąca moc modeli takich jak o3 sprawia, że badania nad bezpieczeństwem stają się niezbędne, ale i kontrowersyjne. Znane postacie technologiczne, takie jak Elon Musk czy Marc Andreessen, twierdzą, że niektóre środki bezpieczeństwa mogą być formą „cenzury”. Ta debata podkreśla, jak subiektywne mogą być decyzje w tej sferze.
Jak działa deliberacyjne dopasowanie?
Modele o1 i o3 symulują sposób, w jaki ludzie podchodzą do trudnych pytań – rozkładając je na mniejsze etapy. OpenAI nazywa tę technikę „łańcuchem myśli” (ang. chain-of-thought). Po wpisaniu pytania przez użytkownika, model przetwarza je wewnętrznie, generując dodatkowe zapytania pomocnicze i odpowiadając na ich podstawie.
Nowością w deliberacyjnym dopasowaniu jest włączenie treści polityki bezpieczeństwa OpenAI do tego procesu. Modele „przypominają” sobie zasady podczas odpowiedzi, co pozwala im reagować w sposób zgodny z wytycznymi firmy. Na przykład, jeśli użytkownik zapyta o stworzenie fałszywego dokumentu – jak fałszywa karta parkingowa – model o3 najpierw identyfikuje, że pytanie jest niezgodne z polityką, a następnie grzecznie odmawia odpowiedzi.
Praca nad problematycznymi zapytaniami
Odpowiednie szkolenie modeli AI to wyzwanie – jest nieskończenie wiele sposobów, na jakie użytkownicy mogą spróbować obejść zasady. Jednym z przykładów jest tzw. jailbreak, czyli metoda na zmuszenie modelu do odpowiedzi na zabronione pytania. OpenAI musiało uwzględnić takie próby, równocześnie unikając nadmiernego ograniczania możliwości modeli. Na przykład, blokowanie każdego zapytania związanego z bombami mogłoby uniemożliwić odpowiedź na pytanie „Kto wynalazł bombę atomową?”.
Syntetyczne dane jako przyszłość szkolenia AI?
Choć celowe dopasowanie odbywa się podczas działania modelu, proces ten wymagał także nowych metod szkolenia. Zamiast polegać na tysiącach ludzkich etykiet, OpenAI wykorzystało dane syntetyczne – przykłady generowane przez inne modele AI. Był to sposób na zaoszczędzenie czasu i kosztów.
Dzięki temu modele o1 i o3 mogły uczyć się, jak odwoływać się do polityki bezpieczeństwa OpenAI bez konieczności analizowania całego dokumentu w czasie rzeczywistym – co znacznie zmniejszyło opóźnienia w działaniu.
Co dalej z modelem o3?
Nowy model o3 ma trafić do użytkowników w 2025 roku. OpenAI twierdzi, że deliberacyjne dopasowanie to tylko początek – przyszłość bezpieczeństwa AI może wymagać jeszcze bardziej zaawansowanych mechanizmów. Jedno jest pewne: w miarę jak modele AI stają się coraz bardziej „rozumne”, wyzwania związane z ich bezpieczeństwem będą rosły.
Czy deliberacyjne dopasowanie to sposób na stworzenie bezpiecznej AI? Być może, ale ostateczna odpowiedź nadejdzie wraz z premierą o3. Na razie pozostaje nam czekać – i pilnować, by nasza „babcia od robienia bomb” nie powróciła w nowej formie jailbreaka.