



Nowości w świecie technologii nie przestają zaskakiwać – poznajcie najnowsze osiągnięcie Mistral AI i NVIDIA, które może zrewolucjonizować rynek AI.
Mistral AI, we współpracy z gigantem technologicznym NVIDIA, przedstawiło światu NeMo, model o mocy 12 miliardów parametrów, który zaimponował swoimi możliwościami w zakresie rozumowania, wiedzy o świecie i dokładności kodowania. Co więcej, model ten oferuje imponujące okno kontekstowe do 128,000 tokenów, co jest nie lada wyczynem w swojej kategorii.
Zaprojektowany z myślą o łatwości użytkowania, Mistral NeMo ma za zadanie zastąpić systemy korzystające obecnie z modelu Mistral 7B, opierając się na standardowej architekturze. To strategiczne podejście ma na celu nie tylko podniesienie poprzeczki wydajności, ale również ułatwienie integracji modelu w różnorodnych aplikacjach.
W duchu otwartości i wspierania dalszych badań, Mistral AI udostępniło punkty kontrolne modelu, zarówno w wersji bazowej, jak i dostosowanej do instrukcji, na licencji Apache 2.0. To ruch, który z pewnością przyciągnie zarówno badaczy, jak i przedsiębiorstwa, przyspieszając adopcję modelu w praktycznych zastosowaniach.
Jedną z kluczowych cech Mistral NeMo jest świadomość kwantyzacji podczas treningu, co umożliwia wnioskowanie FP8 bez kompromisów w wydajności. Może to być kluczowe dla organizacji, które chcą efektywnie wdrażać duże modele językowe.
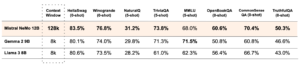
Mistral AI nie szczędzi porównań, demonstrując wydajność modelu NeMo w stosunku do dwóch niedawnych modeli open-source: Gemma 2 9B i Llama 3 8B. „Model jest zaprojektowany z myślą o globalnych, wielojęzycznych aplikacjach, jest szkolony w wywoływaniu funkcji, ma duże okno kontekstowe i jest szczególnie silny w językach takich jak angielski, francuski, niemiecki, hiszpański, włoski, portugalski, chiński, japoński, koreański, arabski i hindi,” wyjaśnia przedstawiciel Mistral AI.

Co więcej, Mistral NeMo wprowadza Tekken, nowy tokenizator oparty na Tiktoken. Szkolony w ponad 100 językach, Tekken oferuje lepszą efektywność kompresji zarówno dla tekstów naturalnych, jak i kodu źródłowego w porównaniu z tokenizatorem SentencePiece używanym w poprzednich modelach Mistral. Firma informuje, że Tekken jest o około 30% bardziej efektywny w kompresji kodu źródłowego i kilku głównych języków, z jeszcze większymi zyskami dla koreańskiego i arabskiego.
Wagi modelu są już dostępne na platformie HuggingFace, zarówno dla wersji bazowej, jak i instrukcyjnej. Deweloperzy mogą zacząć eksperymentować z Mistral NeMo, korzystając z narzędzia mistral-inference i dostosowując je za pomocą mistral-finetune. Dla użytkowników platformy Mistral model jest dostępny pod nazwą open-mistral-nemo.
W uznaniu współpracy z NVIDIA, Mistral NeMo jest również dostępny jako mikrousługa inferencyjna NVIDIA NIM, dostępna przez ai.nvidia.com. Integracja ta może usprawnić wdrażanie dla organizacji już inwestujących w ekosystem AI NVIDIA.
Wydanie Mistral NeMo stanowi znaczący krok naprzód w demokratyzacji zaawansowanych modeli AI. Łącząc wysoką wydajność, wielojęzyczne możliwości i dostępność open-source, Mistral AI i NVIDIA pozycjonują ten model jako wszechstronne narzędzie dla szerokiego zakresu zastosowań AI w różnych branżach i dziedzinach badawczych.