







Kiedy ostatni raz oglądałeś niemy film? Tak, te czasy, gdy wszystko trzeba było wyobrazić sobie samemu, minęły bezpowrotnie. Dzisiejsze modele generowania wideo rozwijają się w zawrotnym tempie, ale wciąż wiele z nich nie potrafi generować dźwięku. A co jeśli moglibyśmy to zmienić? Dziś Google Deepmind dzieli się postępami w nowej technologii video-to-audio (V2A), która umożliwia synchroniczne generowanie obrazu i dźwięku.
V2A łączy piksele wideo z naturalnym językiem, tworząc bogate ścieżki dźwiękowe do akcji rozgrywającej się na ekranie. Technologia ta może współpracować z modelami generowania wideo, takimi jak Veo, aby tworzyć sceny z dramatyczną muzyką, realistycznymi efektami dźwiękowymi lub dialogami, które idealnie pasują do postaci i tonu filmu.
Co więcej, V2A może generować nieograniczoną liczbę ścieżek dźwiękowych dla dowolnego wideo. Możemy nawet definiować 'pozytywne prompty’, które kierują generowane dźwięki w pożądanym kierunku, lub 'negatywne prompty’, które eliminują niepożądane dźwięki.
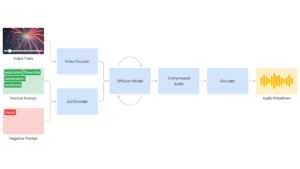
Google eksperymentował z różnymi podejściami AI, aby odkryć najbardziej skalowalną architekturę. Badania pokazały, że metoda dyfuzji daje najbardziej realistyczne i przekonujące rezultaty w synchronizacji wideo z dźwiękiem. Proces zaczyna się od zakodowania wejścia wideo w skompresowaną reprezentację, a następnie model dyfuzji stopniowo poprawia dźwięk z przypadkowego szumu, kierując się wejściem wizualnym i naturalnym językiem.
Aby generować wyższej jakości dźwięk, dodano do procesu treningowego więcej informacji, w tym adnotacje generowane przez AI z szczegółowymi opisami dźwięków i transkrypcjami dialogów. Dzięki temu technologia ta uczy się kojarzyć specyficzne wydarzenia dźwiękowe z różnymi scenami wizualnymi.
System rozumie surowe piksele, a dodanie tekstowego promptu jest opcjonalne. Nie potrzeba też ręcznego dopasowywania wygenerowanego dźwięku do wideo, co jest często czasochłonne.
Oczywiście, nadal istnieją pewne wyzwania do pokonania. Jakość dźwięku zależy od jakości wejściowego wideo. Artefakty czy zniekształcenia mogą prowadzić do spadku jakości dźwięku. Google pracuje również nad synchronizacją ruchu warg z mową, co wciąż bywa problematyczne.
Zanim Google udostępnimy tą technologię szerokiej publiczności, przeprowadzą rygorystyczne oceny bezpieczeństwa i testy.
A więc, czy przyszłość kina to opowieści, które same mówią? Z taką technologią video-to-audio, jesteśmy na dobrej drodze, by to osiągnąć.